
How Unix Works: Become a Better Software Engineer

Unix is beautiful. Allow me to paint some happy little trees for you. I’m not going to explain a bunch of commands – that’s boring, and there’s a million tutorials on the web doing that already. I’m going to leave you with the ability to reason about the system.
Every fancy thing you want done is one google search away.
But understanding why the solution does what you want is not the same.
That’s what gives you real power, the power to not be afraid.1
And since it rhymes, it must be true.
I’ll put just enough commands for us to play along, assuming you’re starting from scratch. We’ll explore concepts, see them in practice in a shell, and then scream “I GET THIS!”. Along the way, we’ll also figure out what a shell really is.
But we can’t begin without getting into the minds of the creators: exploring Unix’s philosophy.
For now, we can assume Linux is Unix. If you want to know why that’s not really the case, you can skip to the bottom and come back. We’ll end the Unix vs linux confusion once and for all.
Philosophy
Let’s start at the core - the philosophy behind Unix.
- Write programs that do one thing and do it well.
- Write programs to work together. (no extra output, don’t insist on interactive input)
- Write programs to handle text streams, because that is a universal interface.
Unix also embraced the “Worse is better” philosophy.
This thinking is powerful. On a higher level, we see it a lot in functional programming: Build atomic functions that focus on one thing, no extra output, and then compose them together to do complicated things. All functions in the composition are pure. No global variables to keep track of.
Perhaps as a direct result, the design of Unix focuses on two major components: Processes and Files.
Everything in Unix is either a process or a file. Nothing else.
There’s a cyclical dependency between processes and files - if we start to go in depth into the explanation of either, we’ll need the other to support it. To break this loop, we’ll start with a brief overview of each and then dive in. And we’ll repeat this a few times to get to the bottom.
Processes
The browser you’re running is a process. So is the terminal, if you have it open.2 If not, now is a good time to open it. If you’re on Windows, docker works really well too. If you’re on a Mac, you can just use the cmd on mac - it’s a unix environment.
In more abstract terms, a process is a running instance of code. The operating system gives resources to the process (like memory), then attaches some metadata to it (like who’s the owner), and then runs the code.
The operating system, as a part of the resources, also provides 3 open files to every process: stdin, stdout and stderr.
Files
Everything that is not a process is a file.
Yes, this means your printer, scanner, the terminal screen, the code for any process! They’re all files. If this sounds confusing, read on. We’ll clear this out.
Your files on the filesystem are files - a string of bytes strung together to create something meaningful. Your photos are files. Your directories are files too! They just contain a list of files/directories present in current directory, exactly like a tree.
The beauty of this is that I can “open” a directory file to see the contents as well!
For example:
$ vim .
" ====================================================================
" Netrw Directory Listing (netrw v162)
" /Users/Neil/examples
" Sorted by size
" Quick Help: <F1>:help -:go up dir D:delete R:rename s:sort-by
" x:special
" ===================================================================
../
./
git-example/
unix-git/
unix-file-system-example/
I used Vim to open a file called .. Does this sound familiar? It’s how Unix stores the current directory. As you can see, it contains a list of files/directories in the current directory.
A file is just a stream of data.

Files and the File System
With the idea of “Everything is a file” and “a file is a stream of data” in place, we can explore how things work further.
On a unix system, the streams for getting input and writing output are predefined. This is precisely what Standard Input, stdin, Standard Output, stdout and Standard Error, stderr are for.
-
stdinis the input data source. -
stdoutis the output data source. -
stderris the standard error output source.
In a shell3, the stdin is input data from your keyboard, and both stdout and stderr are the screen.4
Now, we can redirect these streams to somewhere else, and our program doesn’t have to know! Irrespective of where the input comes from (keyboard or a text file), for any running process, it’s coming from stdin. Likewise for stdout and stderr. We’ll talk more about this when we get to processes which work with these streams.
iNodes
To have a file system in place, you need a structure to manage the filesystem. There isn’t just data in the file to take care of, but information about the data itself, called metadata. This includes where the data is stored, who owns it and who can see it.
This is what inodes are - a data structure for your file metadata. Every file has a unique inode number. This becomes the unique identifier for the file while it exists.
$ ls -li
total 0
2015005 drwxr-xr-x 6 neil X 192 23 Oct 07:36 git-example
2514988 drwxr-xr-x 4 neil X 128 9 Oct 11:37 unix-git/
2020303 drwxr-xr-x 4 neil X 128 23 Sep 11:46 unix-file-system-example/
See those numbers in the first column? Those are the iNodes!5
iNodes store all the metadata. stat is useful for looking at this metadata too.
$ stat -LF .
drwxrwxrwx 7 A B 224 Oct 28 07:15:48 2018 ./
The A and B are the User and Group names. Unix is a multi-user system. This is how Unix does it -
Users and Groups are attributes of a file.
A file with the User attribute set to X means that X owns the file. That’s all a user is to Unix.
224 is the file size, or the number of bytes in the file.
Oct 28 07:15:48 2018 is the date last modified.6
Where did I get all this information from? man ls.
Now come the interesting numbers and characters I’ve left out:
drwxrwxrwx and 7.
File Permissions
Each file has permissions associated with it.
Remember the user and group associated with the file? Every file stores who owns the file and which group the file belongs to. Likewise, every user also has a username and group.
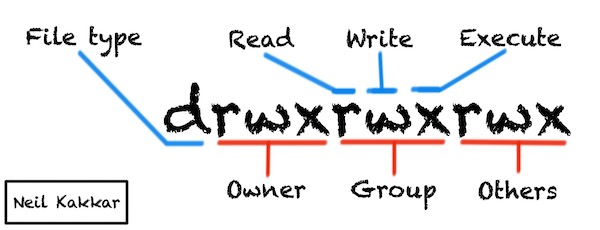
Coming to the -rwxrwxrwx string: this is the permissions for the owner, the group and others.
- r is for reading,
- w is for writing,
- x is for executing. For directories, this means being searchable.
You only need 3 bits to represent permissions for each of user, group and others.
You’ll notice that the string has 10 characters. The first one is a special entry type character to distinguish between directories, symlinks, character streams (stdin), and a few others. man ls to know more.
$ stat -LF
crw--w---- 1 neil tty 16,1 Dec 12 07:45:00 2019 (stdin)
What if you wanted to change permissions? Say I don’t want anyone to search my personal folder (ahem).
The creators of Unix thought about that. There’s a utility called chmod, which can modify permissions on files. In the backend you know now that chmod is interacting with the files inode.
Since we need 3 bits to represent each permission, we can convert that to an integer and pass that to chmod.
For example: chmod 721 . would mean rwx-w---x which means all permissions for the owner, write permissions to the group and execute permissions to others.
I like the verbose form better:
$ chmod u+rwx . # enable user for rwx
$ chmod g+w . # enable group for w
$ chmod o+x . # enable others for x
You’re doing the exact same thing here. To set permissions for everyone, chmod a+x <file> is so much more easier! You could remove permissions as well, using - instead of +.
To restrict access to my personal folder, I’ll do: chmod og-x nothing-interesting-here/.
You can also restrict access to yourself, removing all read, write, and execution permissions for yourself. If the file metadata were stored in the file itself, you wouldn’t be able to change permissions again (since you can’t write to the file). That’s another reason why inodes are cool: they can always be modified by the file owner and root, so you can restore your permissions. Try doing this.
File Linking
Ever wondered why moving a Gigabyte file from one directory to another is blazing fast, while copying the same might take ages? Can you guess why now?
It’s because when we mv, we’re moving the directory structure, not the actual file data. The inodes are a very useful abstraction over the filesystem.
There’s other kinds of moving we can do: we can link files from one place to another, or make two filenames point to the same file.
Two filenames that point to the same file are hard links. Think of them as aliases to a file. You’ve already seen two hard links: . and .. are hard links to current and parent directory on the system.
Links from one place to another are symbolic links. A symbolic link is a new file, separate from original, that links to the original file. These are useful when you want to fix scripts that need to run in a new environment, or to make a copy of a file in order to satisfy installation requirements of a new program that expects the file to be in another location.
$ ls -li
total 0
25280489 -rw-r--r-- 1 neil X 0 8 Dec 08:48 a
$ man ln # to check syntax for hard links
$ ln a x # create x as a hard link to a
$ ls -li
total 0
25280489 -rw-r--r-- 2 neil X 0 8 Dec 08:48 a
25280489 -rw-r--r-- 2 neil X 0 8 Dec 08:48 x
# Notice both files have the same inode number.
# Modifying x or a is the same thing - both files get modified together.
$ ln -s a y # create symbolic link to a
$ ls -li
total 0
25280489 -rw-r--r-- 2 neil X 0 8 Dec 08:48 a
25280489 -rw-r--r-- 2 neil X 0 8 Dec 08:48 x
25280699 lrwxr-xr-x 1 neil X 1 8 Dec 08:54 y -> a
# y is a symbolic link, a new small file - see size is 1.
$ cat y # shows that y (a) is empty
$ echo lsd >> y
$ cat y
lsd
$ cat a # modifying y modifies a
lsd
$ cat x # a is x
lsd
I’ve explained what’s happening above in the comments.
Now what happens if you remove a, the file that y points to?
$ rm a
$ cat y
cat: y: No such file or directory
# y becomes useless
$ ls -li
25280489 -rw-r--r-- 1 neil X 12 8 Dec 08:56 x
25280699 lrwxr-xr-x 1 neil X 1 8 Dec 08:54 y -> a
This is a dangling symlink. It’s useless.
The number after read-write permissions, or the 7 from when we did stat -LF . is the count of hard links to a file.
When I created x, the number went up to 2. When I removed a, the number went back down to 1.
We can also confirm that . and .. is indeed a hard link. Can you think how?
$ ls -ail
25280488 drwxr-xr-x 7 neil X 224 9 Dec 20:19 .
1289985 drwxr-xr-x+ 83 neil X 2656 10 Dec 08:13 ..
25390377 drwxr-xr-x 5 neil X 160 9 Dec 19:13 sample_dir
$ cd sample_dir
$ ls -ail
25390377 drwxr-xr-x 5 neil X 160 9 Dec 19:13 .
25280488 drwxr-xr-x 7 neil X 224 9 Dec 20:19 ..
25390378 -rw-r--r-- 1 neil X 0 9 Dec 19:13 a
Check the inode numbers. .. in sample_dir is 25280488, which is same as . in the parent directory. Also, sample_dir in the parent directory is 25390377, which is same as . inside sample_dir.
File Structure
It helps me to imagine the file system like a tree data structure (indeed, that’s what it is). Every node (inode) has a pointer to its parent, itself and all its children. This forms the directory structure.
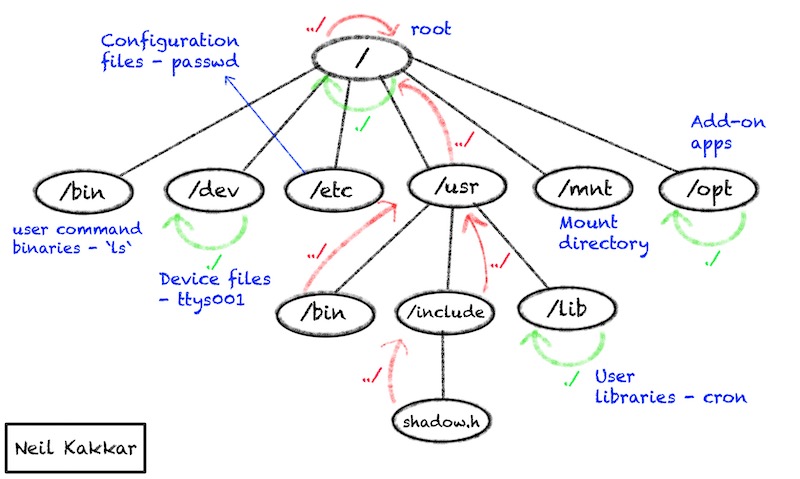
What’s the parent of /, the root directory?
You have enough knowledge to answer this question now. The first thing I did was vim / to see if / has a parent pointer. It does. Then, I did ls -ail to see the iNode of the parent. It points to ., which is /.
In summary,
- The file system is built using inodes and directory files
- Users are attributes of files and processes. This information is stored in the inodes
- iNodes are unique within a file system
- Multiple file systems can be mounted and abstracted into one logical tree
Processes
First, let’s get the definitions out of the way. There are three components to remember about a process:
- Program file: the code and data
- Process image: this stores the stack, variables currently defined, data, address space, and more. When it’s time to run, the OS knows exactly how to recreate the process using this image.
- Process: the running program in memory
When a process starts running, it inherits the user ID and group ID from the parent process. This information controls the level of access to the process.
Note:
Access control is crucial for a secure system. This is one of the reasons running bare docker containers in production can be such a problem: it needs to run as root, which means bad things can happen.
We can use setuid or setgid to enable a process to inherit the file owner permissions. setuid allows a process to inherit userID of the file in question.
For example, to change passwords on linux (see this link for Mac) - we need to modify the file /etc/passwd. However, on checking permissions, we see that only root has access to write to this file.7
$ ls -ail /etc/passwd
3541354 -rw-r--r-- 1 root root 681 Nov 28 08:47 /etc/passwd
Thus, when we call /usr/bin/passwd, the utility to help change passwords, it will inherit our userID, which will get access denied to /etc/passwd. This is where setuid comes in useful - it allows us to start usr/bin/passwd as root.
$ ls -al /usr/bin/passwd
-rwsr-xr-x 1 root root 27936 Mar 22 2019 /usr/bin/passwd
The s instead of x in execution permissions shows that this process will run as root.
To set and remove this bit, we can use chmod again.
$ chmod u-s /usr/bin/passwd
$ ls -al /usr/bin/passwd
-rwxr-xr-x 1 root root 27936 Mar 22 2019 /usr/bin/passwd
I did this in docker, so my true filesystem is safe.
Attributes
Like how all files on the filesystem have a unique inode, processes also have their unique identifiers called process IDs, or pid.
Like how all files have a link to their parent directory, every process has a link to the parent process that spawned it.
Like how the root of the filesystem exists (/), there’s a special root parent process called init. It usually has pid 1.
Unlike the root of the filesystem whose parent directory is itself (/), The ppid of init is 0, which conventionally means it has no parent. The pid 0 corresponds to the kernel scheduler, which isn’t a user process.
Note:
systemd is now replacing init on Linux. It solves a few problems with init, and overall more stable. Read more
Lifecycle
There’s a common pattern in Unix on how processes work.
A new child process is created by cloning the existing parent process (fork()). This new child process calls (exec()) to replace the parent process running in the child with the process the child wants to run.
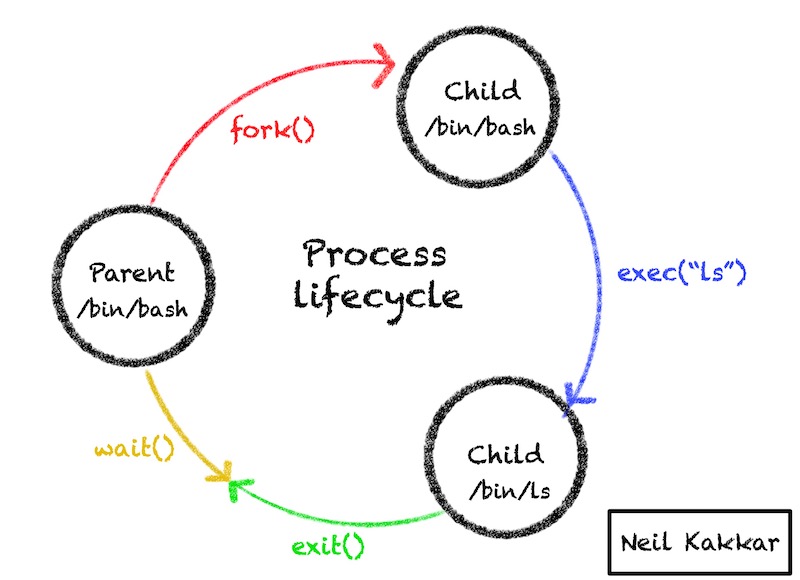
Next, the child process calls exit() to terminate itself. It only passes an exit code out. 0 means success, everything else is an error code.
The parent process needs to call the wait() system call to get access to this exit code.
This cycle repeats for every process spawned.
There are a few things that might go wrong here.
What if the parent doesn’t call wait()? This results in a zombie process - which is a resource leak, since the OS can’t clean up processes before their exit code has been consumed by the parent.
What if the parent dies before the child process? This results in an orphan process (I promise I’m not making this up). An orphan process is adopted by the init process (the special root parent), which then waits on the child process to finish.
In the natural order of the computer world, children die before parents.
How can the parent get access to more information from the child? It can’t via exit codes, since that’s the only thing a process can return to the parent. Processes aren’t like regular functions where you can just return the response to the calling function. However, there are other ways to do inter process communication
We will go into more detail about how things work with an example. Before that, we need a bit more information.
File redirection
Remember how the OS provides 3 open files to every running process? It’s in our power to redirect these files to whatever we want.
> redirects stdout, 2> redirects stderr , and < redirects stdin.
For example, ./someBinary 2>&1 redirects stderr to stdout.
0,1,2 are shorthand for stdin, stdout, stderr files respectively.
Note:
./someBinary 2>1 wouldn’t work like you expect it to, because the syntax is
file-descriptor > file. 2>1 means stderr will be redirected to a file called 1. The & operator gives file descriptor from file.
The file redirection happens before the command runs. When the OS opens the new files (via >), it deletes everything that’s in those files already.
Therefore
sort res.txt > res.txt won’t work.
$ cat res.txt # check contents of res
d
c
b
a
$ sort res.txt # sort res
a
b
c
d
$ sort res.txt > res.txt
$ cat res
# empty
Tip:
You can ensure none of your redirects clobber an existing file by setting the noclobber option in the shell.
$ set -o noclobber
$ sort res.txt > res.txt
-bash: res.txt: cannot overwrite existing file
It would however, work with >>, since in this case you’re appending to the file.
$ sort res.txt >> res.txt
$ cat res.txt
d
c
b
a
a
b
c
d
Layers in Unix
We can think of Unix like an onion. At the center is the hardware - the motherboards, the CPUs, and lots of transistors I don’t quite understand. One layer out is the kernel.
The Kernel
The kernel is the core responsible for interaction with file system and devices. It also handles process scheduling, task execution, memory management, and access control.
The kernel exposes API calls for anything built on top to leverage. The most popular ones are exec(), fork(), and wait().
Unix Utilities
Another layer up are the unix utilities. These are super helpful processes that help us interact with the kernel. They do this via system calls like exec() and fork(), which the kernel provides.
You’ve probably heard of a lot of utilities already. You’ve probably used the most famous one: shell.
Others include: python, gcc, vi, sh, ls, cp, mv, cat, awk.
You can invoke most of them from the shell. bash, zsh, ksh are just different variants of a shell. They do the same thing.
Another utility that people find daunting is the text editor Vim. Vim deserves its own post, and that’s what I’ve created here
Fun Fact:
A shell is called a shell because it’s the closest layer outside the kernel. It covers the kernel in a protective … shell.
How the shell works
Remember how shell is a process? Which means when it’s started, the OS provides three files for it to work with: stdin, stdout, and stderr.
When run from the terminal, stdin is connected to the keyboard input. What you write is passed into the terminal. This happens via a file called tele typewriter, or tty. stdout and stderr is connected to tty too, which is why the output and errors of any command you run show up in the terminal.
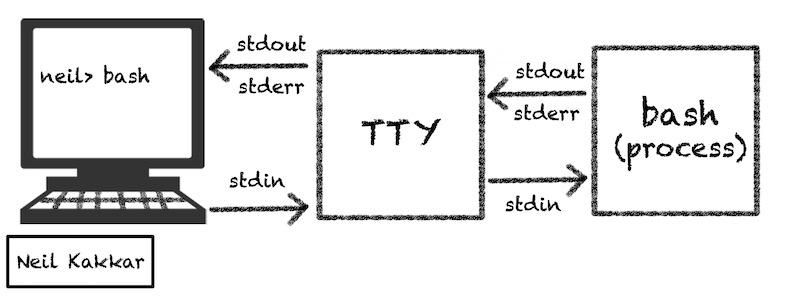
Every terminal you open gets assigned a new file via tty, so that commands from one terminal don’t clobber another. You can find out the file your terminal is attached to via the tty command.
$ tty
/dev/ttys001 # on linux, this looks like: /dev/pts/0
Now you can do something funky: since shell reads from this file, you can get another shell to write to this file too, or clobber the shells together. Let’s try. (Remember how to redirect files from the process section above?)
Open a second terminal. Type in:
$ echo "Echhi" > /dev/ttys001 # replace /dev/ttys001 with your tty output
Notice what happens in the first terminal.
Try echoing ls, the command to list files this time. Why doesn’t the first terminal run the command?
It doesn’t run the command because the stream writing to the terminal was the stdout of the second terminal, not the stdin stream of the first terminal. Remember, only input coming in via stdin is passed as input to the shell. Everything else is just displayed to the screen. Even if it happens to be the same file in this case, it’s of no concern to the process.
The natural extension of the above then, is that when you redirect stdin, then the commands should run. Sounds reasonable, let’s try it out.
Warning:
One way to do this is bash < /dev/ttys001 . This doesn’t work too well, because there are now two processes expecting input from this one file. This is an undefined state, but on my Mac, one character went to one terminal, the other character went to the second, and this continued. Which was funny, because to exit the new shell I had to type eexxiitt. And then I lost both shells.
$ echo ls > ls.txt # write "ls" to a file
$ cat ls.txt # check what's in file
ls
$ bash < ls.txt
Applications
Music
Documents
Downloads
There’s a nicer way to do this, which we’ll cover in a bit.
There’s something subtle going on here. How did this new bash process (which we’re starting from an existing bash process) know where to output things? We never specified the output stream, only the input stream. This happens because processes inherit from their parent process.
Every time you write a command on the terminal, the shell creates a duplicate process (via fork()).
From man 2 fork:
The child process has its own copy of the parent’s descriptors. These descriptors reference the same underlying objects, so that, for instance, file pointers in file objects are shared between the child and the parent, so that an lseek(2) on a descriptor in the child process can affect a subsequent read or write by the parent. This descriptor copying is also used by the shell to establish standard input and output for newly created processes as well as to set up pipes.
Once forked, this new child process inherits the file descriptors from the parent, and then calls exec (execve()) to execute the command. This replaces the process image.
From man 3 exec:
The functions described in this manual page are front- ends for the function execve(2).
From man 2 execve8:
File descriptors open in the calling process image remain open in the new process image, except for those for which the close-on-exec flag is set
Thus, our file descriptors are same as the original bash process, unless we change them via redirection.
While this child process is executing, the parent waits for the child to finish. When this happens, control is returned back to the parent process. Remember, the child process isn’t bash, but the process that replaced bash. With ls, the process returns as soon as it has output the list of files to stdout.
Note:
Not all commands on the shell result in a fork and exec. Ones that don’t are called builtin commands. Some are builtin out of necessity - since child processes can’t pass information back to parents, others to make things faster. For example, setting environment variables won’t work in a subshell, it can’t pass the value back to the parent shell. You can find the list here
Here’s a demonstration I love.
Have you ever thought how weird it is that while something is running and outputting stuff to the terminal, you can write your next commands and have them work as soon as the existing process finishes?
$ sleep 10;
ls
cat b.txt
brrr
# I stop typing here
$ ls
b c y
$ cat b.txt
defbjehb
$ brrr
-bash: brrr: command not found
It’s only the process that’s blocked, the input stream is still accepting data. Since the file we’re reading / writing to is the same (tty), we see what we type, and when the sleep 10; returns, the shell creates another process for ls, waits again, then same for cat b.txt, and then again for brrr. I used sleep 10; to demonstrate because the other commands happen too quickly for me to type anything before control returns to the parent bash process.
Now is a good time to try out the exec builtin command (it replaces current process so it will kill your shell session)
exec echo Bye
echo is a builtin command too.
If you’d like to implement the shell yourself in C, here’s a resource I recommend
The Pipe
Armed with the knowledge of how shell works, we can venture into the world of the pipe: |.
It bridges two processes together, and the way it works is interesting.
Remember the philosophy we began with? Do one thing, and do it well. Now that all our utilities work well, how do we make them work together? This is where the pipe, |, pipes in. It represents the system call to pipe() and all it does is redirect stdin and stdout for processes.
Since things have been designed so well, this otherwise complex function reduces to just this. Whenever you’re working with pipes, or anything on the terminal, just imagine how the input and output files are set up and you’ll never have a problem.9
Let’s start with a nicer way to direct input to bash, instead of using a temp file like we did earlier (ls.txt)
$ echo ls | bash
Applications
Music
Documents
Downloads
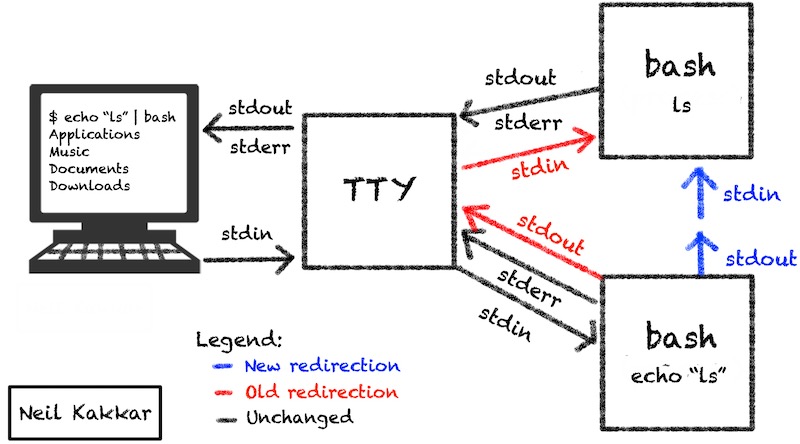
This image is a bit of a simplification to explain the pipe redirection. You know how the shell works now, so you know that the top bash forks another bash connected to tty, which produces the output of ls. You also know that the top bash was forked from the lower one, which is why it inherited the file descriptors of the lower one. You also know that the lower bash didn’t fork a new process because echo is a builtin command.
Lets wind up this section with a more complex example:
$ ls -ail | sort -nr -k 6 | head -n 1 | cut -f 9 -d ' '
2656
This pipeline figures out the largest file in the current directory and outputs its size. There’s probably a more elegant way to do this that is just one google search away but this works well as an example. Who knew this was built into ls already.
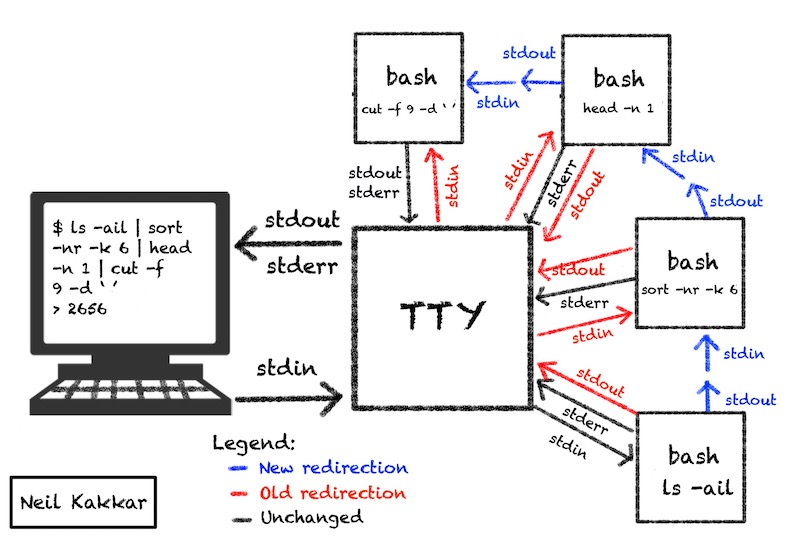
Notice how stderr is always routed directly to tty? What if you wanted to redirect stderr instead of stdout to the pipe? You can switch streams before the pipe.
$ error-prone-command 2>&1 >/dev/null
Source: this beauty
Everything about PATHs
Local variables are ones you can create in a shell. They’re local to the shell, thus not passed to children. (Remember, every non-builtin command is in a new shell which doesn’t have these local variables)
Environment variables (env vars) are like global variables. They are passed to children. However, changes to the environment variables in child process can’t be passed to the parent. Remember, there’s no communication between child and parent except the exit code.
Try this: call bash from bash from bash. The first bash is waiting on the second bash to exit, while the second one is waiting for the third one. When you call exec, the exit happens automatically. If not, you want to type exit yourself to send the exit code to the parent. Exit twice, and you’re back to original.
Now, thought experiment: What happens when you type ls into a shell? You know the fork(), exec() and wait() cycle that occurs, along with tty. But, even before this happens, ls is just another utility function, right? Which means there’s a program file somewhere which has the C code that does fork() and everything else.
This binary isn’t in your current directory (you can check with ls -a). It would’ve made sense to me that if these files were in my current directory: I could execute them by typing their name in the shell. They’re executable files.
Where is the ls program file, exactly?
Remember how the file system tree is heirarchical? There’s an order to the madness. All the base level directories have a specific function. For example, all unix utilities and some extra programs go into the /bin directory. Bin stands for binaries. There’s a million tutorials if you want to find out more.
This is enough knowledge for us. ls lives in /bin. So, you can do this:
$ /bin/ls
a b c
which is same as running ls.
But how did the shell know to look for ls in bin?
This is where the magical environment variable, PATH comes in. Let’s look at it first.
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
and to see all environment variables, we can do
$ env
HOSTNAME=12345XXXX
TERM=xterm
TMPDIR=/tmp
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
PWD=/test
LANG=en_US.UTF-8
SHLVL=1
HOME=/root
LANGUAGE=en_US:en
LESSOPEN=||/usr/bin/lesspipe.sh %s
container=oci
_=/bin/env
The PATH is a colon separated list of directories. When the shell sees a command without an absolute path, it looks in this $PATH environment variable, goes to each directory in order, and tries to find the file in there. It executes the first file it finds.
Notice how /bin is in the PATH, which is why ls just works.
What happens if I remove everything from the PATH? Nothing should work without an absolute path.
$ PATH='' ls
-bash: ls: No such file or directory
The above syntax is used to set the environment variables for just one command. The old PATH value still exists in the shell.
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
Note:
Doing PATH='' echo $PATH wouldn’t work since echo is a shell builtin. However, if you started a new shell process with PATH='' and then did echo, it would work.
$ (PATH=''; echo $PATH)
The () is syntax for a new subshell. I know, it’s a lot of information I’m not explaining first, but it’s all syntax level and just one google search away. On the plus side, it ensures that this blog post doesn’t turn into a book.
Have you heard that ./ is the way to run files you create? Why can’t you just run them like bash ? Now you know. When you do ./, that’s an exact path to the file you want to execute. bash works because it’s on the PATH.
So, it makes sense that if the current directory were always on the PATH, your scripts would work by name.
Let’s try this.
$ vim script.sh
# echo "I can work from everywhere?"
$ chmod a+x script.sh
$ ls
script.sh
$ script.sh
-bash: script.sh: command not found # not on PATH
$ ./script.sh # path to file is defined
I can work from everywhere?
Now let’s add it to current PATH. And then run just script.sh
$ PATH=${PATH}:. script.sh # this appends . to PATH, only for this command
I can work from everywhere?
$ export PATH=${PATH}:. # this sets the PATH variable permanently to include .
$ script.sh # calling script.sh without the ./
I can work from everywhere?
$ cd .. # go one directory up
$ script.sh # this shows that PATH directories aren't searched recursively
-bash: script.sh: command not found # so script doesn't run anymore
Warning:
It’s bad practice to include the current directory in your PATH. There are several problems -
- You can never be sure that execution of any command acts as intended.
- What if you have a binary called
lsthat’s a virus in your current directory (downloaded from the internet), but you meant to do/bin/ls? - Read more
Next time you see a “no such file or directory” error, when you know the file exists (maybe you just installed it) - you know what the issue is. The PATH is busted! Its either installed to a location not on your PATH so you can only call it from the place you installed it to. To fix this, you now know that you can either add that directory to the PATH, or call the file via its absolute path.
Fun Fact:
Python has a similar structure when searching for imports, which uses PYTHONPATH env variable.
Note:
Under the hood, the shell looks for a / in the command to figure out whether to search on PATH or not. Thus, ./script.sh isn’t searched in PATH, and neither is unix-example/script.sh, even though it’s a relative path.
Writing Shell scripts
This post has already become much longer than I expected. Also, programming with shell has been covered online a lot. But for completeness sake, here’s a link to the manual, and a decent tutorial.
Package Managers
Let’s say you’ve written a new tool. It works really well on your machine and now you want to sell it to other users. Wait, I mean, in the spirit of open source, you want to make it available for others to use. You also want to save them the PATH headaches. Better yet, you want things to be installed in the right place: the binary goes into /usr/bin/ (it’s already on PATH) and the dependencies go somewhere where the main binary can find it.
Package managers solve exactly this problem. Instead of giving you headaches, they just make things work™.
There are three main package managers I know of: dpkg, rpm, and homebrew. Each of them works on a different linux distribution (if you’re not sure what that means, it’s in the next section) But, there’s hundreds of them in the wild, just like the number of distributions.
dpkg is the debian package manager, but you’ve probably heard of a very useful tool built on top of it to manage packages: apt.
Every time you use apt install to install a new package, you’re leveraging the power of this package manager which ensures things end up where they need to be. On the development side, this means ensuring that the tool you’re creating is compatible with the package manager. For example, here’s how to do it in C and Python.
rpm is the RedHat Package manager, which also has a useful tool built on top: yum, which takes care of dependencies too.
homebrew is the package manager on MacOS, and you’re using it every time you brew install something.
They make life easy.
They’re so convenient, that programming languages have their own package managers too! For example, pip is a popular Python tool installer. There’s bundler for Ruby, cocoa for Swift/iOS, and several others.
Brief History of Unix
Unix was the first of its kind operating system that allowed multiple users to use it, and every user could run more than one program at the same time. This might sound trivial now, since almost every operating system has this, but it was revolutionary when it first came out. The days of leasing time on a big mainframe were over. You could let your program run in the background while someone else did their work.
As the definition goes, Unix is a multi-user multi-tasking operating system.
This was proprietary, and AT&T was the only company that could sell it. (Bell labs developed it in the 1970s). They opted for a licensing model, and soon came out with a specification, called the Single UNIX Specification. These were a set of guidelines, and any system that followed them could be certified as a UNIX system.
Around the same time, some people were unhappy with the proprietary nature of UNIX, and came up with another open source operating system kernel called Linux. Inspired by the UNIX philosophy, and to enable portability, these systems adhere to the POSIX standard, which is a subset of UNIX. These systems are thus also called UNIX-like.10
Fun Fact:
Linux was made possible by the GNU Project. These were a set of tools for development, like the GNU C compiler (gcc), and shell utilities, like ls, grep, awk. Even bash!. Linux probably wouldn’t have been possible without the GNU Project. What’s a kernel without the shell?
This is why Linux is sometimes referred to as GNU/Linux as well.
Things get a bit confusing here. Linux is a family of operating systems based on the Linux kernel. There is no single operating system called Linux. What we do have instead, are debian, ubuntu, fedora, centOS, Red Hat, gentoo, etc. These are distributions (popularly called distros) of the Linux kernel. Full fledged operating systems.
What’s the difference? Some are built for a specific purpose (for ex: Kali linux comes built with security testing tools).
Most differ in package management, how often packages are updated, and security.
If you’d like to know more, go here
Fun Fact:
Mac OS X is UNIX certified.
Conclusion
We’ve covered a lot. Let’s take a moment to put it all together.
UNIX is a full fledged operating system, and Linux is a kernel - the core of the operating system - inspired by Unix. They focus on doing one thing, and doing it well. Everything is either a process or a file. The kernel is the core, which exposes system calls, which utilities leverage. Processes work with files as input and output. We have control over these files, we can redirect them, and it wouldn’t make a difference to the process. The pipe can redirect output from one process into the input for another. Every command from shell first forks, then execs, and returns the exit code to the waiting parent.
There’s a lot more. If it were possible to do a lossless compression, I would’ve done it in the post.
So, welcome to the wild, you’re good to go.
exit
Thanks to Vatika Harlalka, Nishit Asnani, Hemanth K. Veeranki, and Hung Hoang for reading drafts of this.
Footnotes
-
Did this just become a poem? ↩
-
The terminal has subprocesses running as well, like the
shell. You can look at all running processes viaps -ef. ↩ -
A
shellis the interface you use to interact with the operating system. It can be both, a command line interface (CLI), and graphical user interface (GUI). In this post, we focus just on the CLI. When you open a terminal, the default program that greets you is ashell. Read more ↩ -
This isn’t 100% right, there’s a bit more nuance to it, which we’ll get to soon. ↩
-
I’ve been spending too much time with iPhones and iOS. It’s an inode, not an iNode. ↩
-
Also the time when I started writing this guide. About time I finished it. Notice the year. ↩
-
I got all this information from
man 5 passwd↩ -
The manual has 8 sections, each for a specific purpose. Read more. ↩
-
This is a powerful idea, which is true only because Unix by design says “Everything is a file”. ↩
-
Fun fact - they can’t be called UNIX because they haven’t been certified, and UNIX is a trademark. ↩
You might also like
- Things I Learnt from a Senior Software Engineer
- Where do analogies break down?
- How not to be afraid of javascript anymore
- How Not to Be Afraid of Git Anymore