
Things I Learnt from a Senior Software Engineer
A year ago, I started working full-time at Bloomberg. That’s when I imagined writing this post. I imagined myself to be full of ideas that I could spit out on paper when the time comes. Just one month in, I realised it won’t be that easy: I was already forgetting things I learnt. They either became so internalized that my mind tricked me into believing I always knew them1, or they slipped my mind.
That’s one of the reasons I started keeping a human log. Every day, whenever I came across an interesting situation, I logged it. All thanks to sitting next to a senior software engineer, I could closely observe what they were doing, and how it was different from what I would do. We pair-programmed a lot, which made doing this easier. Further, in my team culture it’s not frowned upon to “snoop behind” people writing code. Whenever I sensed something interesting going on, I’d roll around and watch what was happening. I always had the context, thanks to regular standups.
I sat next to a senior software engineer for a year. Here’s what I learnt.
Writing code
How to name stuff
One of the first things I worked on was a React UI. We had a main component housing every other component. I like a bit of humour in my code, and I wanted to name it GodComponent. Come code review time, and that’s when I understood why naming things is hard.
There are two hard things in computer science: cache invalidation, naming things, and off-by-one errors. - Leon Bambrick
Every code piece I baptize has an implicit meaning attached to it. GodComponent? That’s the component where all the crap I can’t be bothered to fit in the right place goes. It houses everything. Had I called it LayoutComponent, future-me would realise that all it does is assign the layout. It holds no state.
Another great benefit that I found out was this: If it seems too big, like a LayoutComponent containing tonnes of business logic, I’ll know it’s time to refactor, because the business logic doesn’t belong there. With the name GodComponent, the business logic in there wouldn’t make a difference.
Naming your clusters? Naming them after the service that runs on them is great, till the point you start running something else on them too. We ended up naming them with our team name.
It’s the same idea with functions. doEverything() is a terrible name, and the ramifications are plenty. If this function does everything, it’s going to get bloody difficult to test the specific parts of the function. No matter how big this function gets, you’ll never think it’s too weird, since after all, the function is supposed to do everything. Change name. Refactor.
Meaningful naming has a flip side to it, too. What if the name is too meaningful and hides some nuance? For example, closing sessions doesn’t close the underlying DB connection when you call session.close() in SQLAlchemy. (I should’ve RTFM and prevented that bug - more about that in Debugging)
In this case, thinking of names as x, y, z instead of count(), close(), insertIntoDB() prevents assigning implicit meaning to them - and forces me to scrutinize what they are doing.2
I never imagined I’ll have more than one line to say about how to name stuff.
Legacy code and the next developer
Have you ever looked at some code and felt it’s weird? Why do they do it this way? This makes zero sense.
I had the privilege of working with a legacy codebase. The kind with comments like “Uncomment code when situation figured out with Mohammad.” What do you do here? Who is Mohammad?
I can do a role-reversal here - think about the next person coming to my code - will they find it weird or not. Peer reviews solve this somewhat. This led me to the idea of context: Be aware of the context my team is working in.
If I forget about the code, and come back to it later, and I can’t recreate the context, I’ll go like: “Why the f did they do it this way? This makes zero sense… Oh wait, I did this.”
And that’s where documentation and code comments come in.
Documentation and Code comments
They help to preserve context, and share knowledge.
As Li put it in How to Build Good Software, “The main value in software is not the code produced, but the knowledge accumulated by the people who produced it.”
“The main value in software is not the code produced, but the knowledge accumulated by the people who produced it.” - Li
We have this random client facing API endpoint that no one ever seems to use. Do we just delete it? After-all, it’s tech debt.
What if I told you, once every year in a specific country, 10 journalists send their reports to that endpoint? How do you test this? If there’s no documentation (there wasn’t), we can’t. So, we didn’t. We deleted that endpoint. A few months down the line came that time of the year. Ten journalists were unable to send 10 important reports because the endpoint didn’t exist anymore.
The people with the knowledge of the product had left the team. Sure enough, now there are comments in the code explaining what the endpoint is for.
From what I’ve heard, documentation is something every team struggles with. Not just code documentation but processes around the code.
We haven’t yet figured out a perfect solution for this.
I enjoyed Antirez’s breakdown of different types of worthy code comments
Atomic commits
If you have to rollback (and you will. See Testing), does this commit make sense as one unit?
Becoming confident about deleting shit code
I was very uncomfortable deleting shit or obsolete code. I consider what was written eons ago sacred. My thinking goes “They must have something in mind when they wrote this.” It’s tradition and culture vs first principles thinking. It’s the same thing that happened with deleting the once-a-year-endpoint. I learnt too specific a lesson there.3
I’d try to work around the code, the seniors try to work through it. Delete all of it. An if statement that would never be reached? A function that shouldn’t be called? Yep, all gone. Me? I’d just write my function on top. I’ve not reduced tech debt. If anything, I’ve just increased the code complexity and misdirection. The next person would have an even tougher time piecing things together.
The heuristic I now use is this: There’s code you don’t understand, and there’s code you know you’ll never reach. Delete code you’ll never reach, and be cautious with code you don’t understand.
Code Reviews
Code reviews are amazing for learning. It’s an external feedback loop on how you’d write code vs how they write it. What’s the diff? Is one way better than the other? I asked myself this question with every code review I did: “Why did they do it this way?”. Whenever I couldn’t find a suitable answer, I’d go talk to them.
After the first month, I started catching mistakes in my teammates codes (just like they were doing for mine). This was insane. Peer reviews became a lot more fun for me - it was a game I looked forward to - a game to improve my code-sense.
My heuristic: Don’t approve code till I understand how it works.
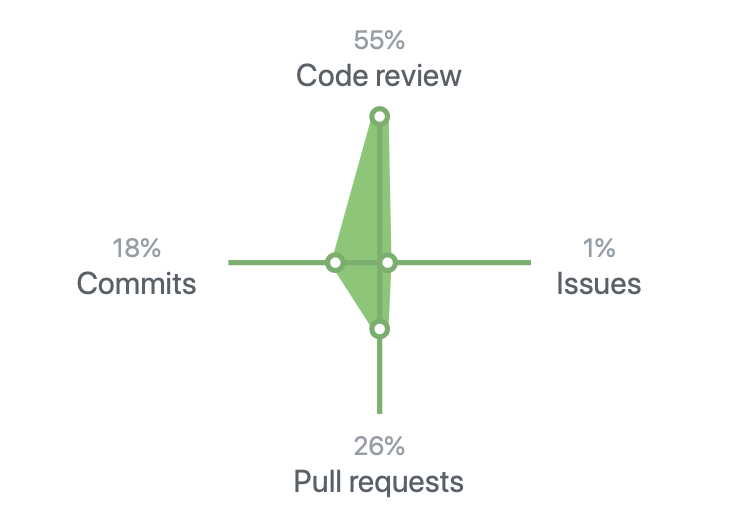
My Github stats
Testing
I’ve come to love testing so much that I feel uncomfortable writing code in a codebase without tests.
If your entire application does one thing (like all my school projects), then testing manually is still okay4. That’s what I used to do. But what happens when there are 100 different things the application does? I don’t want to spend half an hour testing everything, and sometimes forgetting what all I need to test. That’s a nightmare.
Here come tests and test automation.
I think of testing as documentation. It’s documentation for my assumptions about the code. Tests tell me how I (or the person before me) expect the code to work, and where all they expect things to go wrong.
So, when I write tests now, I write with this in mind:
- Show how to use the class/function/system I’m testing.
- Show what all I think can go wrong.
A corollary of the above is that in most cases, I’m testing the behaviour, not the implementation. (Here’s an example I picked up during bathroom breaks at Google)
The things I miss in #2 is where the bugs come from.
So, whenever I spot a bug, I make sure that the code-fix has a corresponding test (called regression testing) to document the information: This is another way things can go wrong.5
However, just writing these tests doesn’t improve my code quality, writing the code does. But the insights I gain from reading the tests help me write better code.
That’s the big picture of testing.
But, that’s not the only kind of testing to do. This is where deployment environments come in.
You may have perfect unit tests, but if you don’t have system tests, something like this happens:

The lock works(?) Source
This holds true for well tested code too: If you don’t have the libraries you need on your machines, you’ll crash and burn.
-
There’s the machines you develop on (source of all “It works on my machine!” memes).
-
There’s the machines you test on (might be the same as the ones you develop on).
-
Finally, there’s the machines you deploy on (please don’t let this be the same as the machines you develop on)
If there’s an environment mismatch between test and deploy machines, you’ll be in trouble. And here’s where deployment environments come in.
We have local development, which is in docker - on my machine.
We have a dev environment, where machines have a set of libraries (and dev tools) installed and we install the code we write on these. All testing with other dependant systems can take place here.
Then comes the beta / stage environment, which is exactly like the production environment.
Finally, the prod or production environment, which are the machines on which the code runs and serves actual customers.
The idea is to try and catch errors that unit and system testing wouldn’t. For example, an API mismatch between requesting and responding system.
I guess things would be very different in a personal project or a small company. Not everyone has the resources to setup their own infrastructure. However, the idea still holds with cloud providers like AWS and Azure.
You can have separate clusters set up for dev and prod. AWS ECS uses docker images to deploy, so things are relatively consistent across environments. The tricky bit is the integration between other AWS services. Are you calling the right endpoint from the right environment?
You can even go a step further: Download alternate container images for the other AWS services and setup a local full-fledged environment using docker-compose. It accelerates feedback loops.6
I’ll probably have more experience here once I get my side project up and running.
Derisking
De-risking is the art of reducing risk with the code that you deploy.
What all steps can you take to reduce the risk of disaster?
If it’s a new breaking change, how can you ensure minimal disruption when things go wrong?
“We don’t need to do a full-system deploy with all those new changes.” Oh, wait, really? How did I never think of this!
Design
Why am I putting design after writing code and testing? Well, design might come first, but if I haven’t coded and tested in the environment I’m in, I probably wouldn’t be great at designing a system that respects the quirks of the environment.7
There’s so much to think about when designing a system.
- What’s the usage numbers?
- How many users exist? and what’s the expected growth? (This will translate into how many db rows)
- What might be the future pitfalls?
I need to convert this into a proper checklist titled “Gathering Requirements.” I haven’t had enough experience with it this year, which is something to solve in my next year at Bloomberg.
This process goes a bit against Agile - how much can you design before getting to the implementation? It’s a balance - and you need to choose when to do what. When does diving in headfirst make sense, and when does taking a step back?
Of course, just gathering requirements isn’t everything to think about. I think it pays off to include the development processes in design as well. Things like
- How will local development work?
- How will we package and deploy?
- How will we do end-to-end testing?
- How will we stress-test this new service?
- How will we manage secrets?
- CI/CD integration?
We recently developed a new search system for BNEF. Working on this was wonderful. I got to design local development, learn about DPKGs (packaging and deployment), and wrestled with secret deployment.
Who thought deploying secrets to production can get that tricky?
- You can’t put them in code, as then anyone can see them.
- Put them as an env variable, like the 12 factor app suggests? It’s a good idea. How do you put them there? (Accessing PROD machines to populate env variables everytime the machine starts is a pain)
- Deploy as a secrets file? Where does the file come from? How is it populated?
We don’t want things to be manual.
In the end, we went with a database with role access control (only our machines and us can talk to the database). Our code gets the secrets from this database on startup. This replicates very well across dev, beta and prod - with secrets in the respective databases.
Again, this can be very different with a cloud provider like AWS. You don’t have to think much about secrets. Get your role account, input secrets in the UI, and your code shall find them when it needs them. It’s pretty cool how much it simplifies things - but I’m glad to have the experience to appreciate the simplicity.
Designing with maintenance in mind
Designing systems is exciting. Maintaining them? Not so much.
My journey through maintenance led me to this question. Why and how do systems degrade?
First part is not deprecating old stuff, always adding more. A bias towards addition instead of deletion. (Reminds you of someone?)
The second part is designing with an end goal in mind. A system that evolves to do things it wasn’t supposed to do necessarily doesn’t work as well as a system designed from scratch to do the same thing. This is the taking-a-step-back approach instead of hacking away with agility.
I now know of at least three ways to reduce rate of degradation.
- Keep the business logic and the infrastructure separate: It’s usually the infrastructure that degrades - usage increases, frameworks become obsolete, zero-day vulnerabilities show up, etc.
- Building processes around maintenance. Apply the same updates to new bits and old bits. This prevents diff between new and old, and keeps the entire code “modern”.
- Ensure you keep pruning all your unwanted/old stuff.
Deploying
Would I rather bundle features together or deploy them one by one?
Depending on the current processes in place, if the answer is to bundle features together, there’s a problem.
The question to ask then is why do you want to bundle features together?
- Does the deployment take too much time?
- Do the code reviews not happen easily?
Whatever is the reason, that’s the bottleneck to fix.
I know at least two issues with bundling.
- You’re self blocking one feature if bugs in the other.
- You’re going anti-derisking, or increasing risk of things going wrong.
Then, whatever deployment process you choose, you always want your machines to be like cattle, not like pets. They aren’t precious. You know exactly what’s running on every machine, and how to recreate them in case of death. You’re not upset when one machine dies, you just spin up a new one. You herd them, not raise them.
When things go wrong
For when things go wrong, and they will, the golden rule is minimizing client impact.
My natural tendency when things went wrong were to fix the problems. Turns out, it’s not the most optimal solution.
Instead of fixing what went wrong, even if it’s a “one line change”, the first thing to do is rollback. Go back to the previous working state. This is the quickest way to get clients back on a working version.
Only then should I look at what went wrong and fix those bugs.
Same idea with a “borked” machine in your cluster - put it down, mark it unavailable, before trying to figure out what’s wrong with the machine.
I found this weird, how my natural tendency and instincts diverge from the optimal solution.
I think this instinct also leads me down the longer path to solving bugs. Sometimes, I figure it’s not working because there’s something wrong with what I wrote, and I’d get into the weeds going through every line of code I wrote. Something like depth-first search.
When it turns out to be a config change, that is, I didn’t enable the feature in the first place, it pisses me off. I was so sub-optimal in the bug discovery process.
Since then, my heuristic has been to do a breadth-first search before a depth-first search, to get rid of the top level nodes. What can I confirm using current resources?
- Is the machine up?
- Is the right code installed?
- Is the config in place?
- < Code specific configuration >, like is the routing in the code correct?
- Is the schema version correct?
- Then, get into the code.
We thought nginx didn’t install properly on the machine, but turns out, just the config was set to false.
Of course, I don’t need to do this always. Sometimes, just the error message is enough to cut down the search space right to my code.
When I can’t figure out the issue, I try and keep the changes-to-code-to-figure-out-what’s-wrong to a minimum. The less the number of changes, the faster I can hone in on the real issue. Keep the inferential jumps to a minimum.
I also now keep a note of bugs that took me more than 1 hour to solve: What was I missing? It’s usually some dumb shit I forgot to check, like setting up routing, making sure the schema version and the service version match, etc. etc. This is another step of getting familiar with the tech stack I use, and one thing that only experience gives - intuition for figuring out exactly why things aren’t working.
War Story
It’s a dance between tweaking parameters, and playing with statistics vs fixing the underlying cause.
How can this post ever be complete without a war story? I enjoy reading them, and I’ve got at least one to share now.
It’s the tale of search and SQLAlchemy. At BNEF, we have lots of analysts writing research reports. Whenever a report is published, we get a message. Whenever we get a message, we go into our database via SQLAlchemy, get all the stuff we need, transform it, and send it to our solr instance for indexing. Now, time for the weird AF bug.
Every morning, connecting to the database would fail with the error “MYSQL server has gone away.” Sometimes, during the afternoon as well. The machines turn during the afternoon, so that’s the first thing I checked. Nope, errors never occurred when the machines were turning. We make thousands of requests throughout the day to the database, none of which fail. How come, then, this very low load trigger would fail?
Oh, maybe we aren’t closing our sessions after the transaction? So if it’s the same session, and the next request comes after ages, we’ve missed the timeout, and the server has gone away. Quick look in the code, and sure enough, we are using a context manager for every read which calls session.close() on __exit__().
After one day of going through everything that might go wrong, getting nowhere, I come in to work next morning and have a chance encounter. The error occurred this morning as well. And one second after the error, three other index requests were successful. This had all the symptoms of an improper session close. You know how this story ends.
Session.close() in the mysql dialect of SQLAlchemy doesn’t close the underlying DB connection, unless you’re using a NullPool. Yep, that was the fix.
It’s funny how this bug occurred simply because we didn’t publish research reports at night and during lunch time. And therein lies another lesson - most stack overflow answers (of course I googled it!) for this bug were to tweak either the session timeout time, or the parameter controlling amount of data you can send per SQL statement. Neither made sense to me, because they were pretty much unrelated to the root issue. I checked that our query size was within the limits, and we were closing the sessions(lol) so timeout wouldn’t occur.
We could have “fixed” this bug by increasing the session timeout value to 8 hours instead of 1 hour. It would’ve appeared to fix the problem, till the next time we have a holiday during the week - and the first research report next morning would fail.
It’s a dance between tweaking parameters, and playing with statistics vs fixing the underlying cause.
Monitoring
This is something I never thought about doing before. To be fair, before coding full time I was never maintaining systems. I just built them, used them for a week and moved on.
Working with two systems, one with great monitoring, and the other not so much, I’ve come to appreciate monitoring a lot. I can’t fix bugs if I don’t know they exist. One of the worst feelings is to find out from clients about bugs. “What am I doing?! I don’t even know things going wrong with a system I own?”
I think three components make up monitoring - logging, metrics, and alarms.
Logging in code, just like the human log, is an evolutionary process.
You figure out things you might need to monitor, you log those, you run your system. Over time, you find a few bugs you don’t have enough information to solve. Those are good times to enhance logging - what’s your code missing?
I think you intuitively figure out what things will be important to log. There was a lot of difference between the kind of things him (the senior SWE) and I were logging in our service. I figured just the request-response logs would suffice, while he had lots of metrics like query execution time, some specific internal calls made by the code, and also when to rotate logs, all sorted out.
It’s virtually impossible to debug things without logs - if you don’t know the state the system was in, how do you even go about recreating it?
Metrics can be derived from logs, or a separate standalone in the code. (Like sending events to AWS CloudWatch and Grafana). You decide your metrics and send the numbers in as the code runs.
Alarms are the glue putting everything together in a great monitoring system. If one metric is the number of machines currently running in production, when this number falls to 50% is a great alarm to have - you know something went wrong.
Failure count above a certain threshold? Yep, another alarm.
I can sleep well at night, knowing if something goes wrong, I’ll be woken up. (Wait, what?)
This hints at another habit to develop. When you fix bugs, you aren’t just focusing on how to fix the bug, but also, why didn’t you figure it out earlier? Was there alarming in place? How can you monitor better to prevent similar problems?
I haven’t yet figured out how to monitor the UI. Testing the components are in place isn’t enough to know about things going wrong. This is usually where clients come in and tell us - things don’t look right.
Conclusion
Over the last year, I’ve learnt a lot. I’m glad I made the decision when I started working to write this post - I can appreciate much better how much I’ve grown when I have this document to look back to. And I hope there’s something you can takeaway from this, too!
I’ve also been pretty lucky to get a great team - we code a lot, we laugh a lot, we get to design systems from scratch, and work with lots of other teams.
This year, I’m sitting next to two senior devs. Let’s see how this goes! Thanks, team!
Good engineers themselves design systems that are more robust and easier to understand by others. This has a multiplier effect, letting their colleagues build upon their work much more quickly and reliably - How to Build Good Software


Things I’m not sure about
I haven’t cracked the code of software engineering, yet. So, this section serves as a reminder for me: There’s so much left to learn! If I’m doing things right, this list should grow longer next year.
-
Think in terms of abstractions or implementations?
-
Should I have strong opinions about how to do things? Maybe as a result of being bitten before? Have I done the work required to have an opinion?
-
Developing processes for workflows. If you need to change how you do things because of an emergency or an event - then is the process broken? Is it something to fix?
-
Are utils (folder where you put random stuff you don’t know where to put otherwise) a code smell?
-
How to deal with documentation for code and workflows?
-
How to monitor UI to see when things don’t look alright?
-
Spending time designing the perfect API / code contract vs hacking it out and iterating over and over again, to figure out what works best. Which one is better?
-
The easy way vs the right way? I’m not convinced the right way is superior always.
-
Doing things yourself vs showing those who don’t know how to do them. The former gets done fast, the latter means you seldom have to do it again yourself.
-
When refactoring and preventing huge-ass PRs: “If I’d have changed all the tests first then I would have seen I had 52 files to change and that was obviously gonna be too big but I was messing with the code first and not the tests.” Is breaking it up worth it?
-
Explore De-risking further. What all strategies exist to de-risk projects?
-
Effective ways of gathering requirements?
-
How to decrease rate of system degradation?
Enjoyed this? I wrote a follow up this year! You can read it here.

Thanks to Hemanth Kumar Veeranki for reading drafts of this.
-
This happens with a lot of things. Do you know how to ride a bicycle? Can you teach someone? Tell them the exact steps you did? ↩
-
This doesn’t mean writing the code with the names
x(), y(), z(), but just thinking of them asx(), y(), z(). Don’t assume WYSIATI ↩ -
The classic Chesterton’s fence. ↩
-
I wouldn’t do this anymore though. Once you cross over to the automated tests side you never go back? ↩
-
There’s an argument about this getting out of hand, by having a million tests for everything that might go wrong. From what I’ve seen, this isn’t really the case, yet. ↩
-
I haven’t done this in a while, so not sure how easy is it to find/build AWS specific docker images. ↩
-
Environment here could mean your tech stack. ↩
You might also like
- The Best Things I Learned In 2019
- Second Order Thinking - A Practical Guide
- How not to be afraid of python anymore
- How Not to Be Afraid of Git Anymore