
How I Own Projects as a Software Engineer
When you take ownership of a project, something changes. You become responsible for everything that happens with the project.
Things go wrong? That’s on you. Customers are unhappy? That’s on you. You shipped something that doesn’t solve the problem? That’s on you.
Ideally, you have a process that reduces the number of ways things can go wrong.
I started at PostHog ~8 months ago. Since then, I’ve been fortunate to own 2 big projects. I’m nowhere near experienced enough to be talking about prescriptions, but that’s not the point. A big part of growing quickly is understanding what you’re doing and why you’re doing it. So, this post is my model of how to own and build new products.
Something magical happens when you own the entire stack. From talking to customers, to deciding what to build, to deciding who will build what, to finally getting feedback, and then redoing this cycle. You see the entire flow, which gives you better context on what to do. Sometimes, software isn’t the way to solve problems.
Broadly, I’ve noticed 5 steps. The goal behind each of these is to increase your chances of success. I’ll explain them, and follow up with metas behind these steps. Finally, since PostHog is open-source, I’ll link to precise real-world examples for what I’m talking about.
Gather Context
Trying to find solutions before you understand the problem will lead you around in circles. First, understand the problem. This begins with understanding the use case.
An interesting project I recently worked on was Experimentation. If you think of it in terms of what you should be building, it would be: “Build an A/B testing platform”. This problem severely lacks context. When you think in terms of what to do, you lose track of what users really wanted.
It also makes it harder to prioritise & figure out what to build. For example, say you’re just starting off with this project. What do you include in the MVP? What are the risky things you need to test quickly? You can’t answer these questions because they’re outside the scope of the problem.
Things are different when you think in terms of the use case. Begin with: “People have trouble A/B Testing because they are missing instrumentation, and the results they get are hard to understand.” This tells you what you need to do: (1) Make instrumentation easy & (2) Make results easy to understand.
Getting to this point is hard, and the first obstacle to building a successful product. To understand the use case, you need to talk to users. Ask questions. Go deep into what they say. Here’s how PostHog does it.
Once you understand the use case, you can judge what problems are related to your own, and whether existing solutions work or not. In a world where similar problems have been solved before, it would be a shame to not understand how others have solved these problems.
Take some time to see how others have solved these problems. With A/B testing platforms, there’s hundreds of them in the wild! What helped me lead this project better was to know how these A/B testing platforms work, which problems they focus on solving, and take inspiration from it.
For example, I realised that most A/B Testing platforms are standalone: they’re unbundled, so instrumentation and deciding on target metrics happens elsewhere (say, your analytics suite), and you come here for doing analysis on the results. Since PostHog already has Feature Flags for instrumentation, and it’s main job is literally an analytics suite, there’s real opportunity for bundling here. This is what governed our thinking about this feature.
Looking at solutions also gives you a better understanding of the risks you might be taking. With experimentation, since our goal was to make results easy to understand, and reduce the number of things users have to know to run a good A/B Test, we decided to test out the Bayesian analysis route. This gets rid of concepts like p-values, statistical significance, confidence intervals, and focuses on a singular value: the probability that your variant is better than the control. For the nitty gritty details, see here
Figure out a solution
Once you have context, you can start thinking of solutions.
One trap I’ve noticed myself falling into is taking inspiration too heavily from existing solutions. How can you build a better version if you repeat the same mistakes they’ve made?
Another trap is thinking only in terms of what’s possible technically. This is specially a problem with engineers. You know how the system works, you know the compromises you’ve made, so you limit the world of possible solutions that fit into these existing constraints. This is a problem, because it often underestimates what’s possible.
The way I evade both these traps is to start with ideal solutions. What solution would completely solve for the usecase? Doing this allows me to tease out the first principles. “What is it about the ideal solution that makes it ideal? What is the crux that solves the problem?”.
For example, with experimentation, I came up with 3 first principles born out of an ideal solution:
- The numbers have to be 100% accurate. No estimation, no rough calculation, no infrastructure affecting the A & B test buckets. Someone who was in bucket A can’t move to bucket B two days later.
- The results should be easy to understand
- There’s a lot more leeway here. Figuring this out well means going back to your users and asking for feedback.
- People should be able to test their changes before launching the A/B test.
- The experiment becomes invalid if both A & B variant are showing the same thing when they shouldn’t be.
What’s very cool about engineers owning products is the conversation you can have with yourself. On one side are the technical constraints: what’s possible given what we have now? On the other side are the use cases: Disregarding all technical constraints, what does the ideal solution look like?
When technical constraints clash against the ideal, I can go back to the first principles. Now, given I want to preserve these principles, how can I solve this problem?
The above question forces me to think of levers I can pull. I often believe that the only lever I have is the technical constraints: What clever optimisations can I do that will make this possible?
But this isn’t true. There’s another powerful lever I have: solving the problem differently. In practice, this means changing the UX, while preserving the first principles.
For example, I clashed against a hard technical constraint in experimentation. It’s not something that can’t be solved, but doing it takes way too much engineering resources. Instead, I opted to change the UX. We’re still respecting the three first principles, it’s just that the creation flow is different from how I expected the ideal one to be.
Worth noting here again are the three principles for experimentation. While (1) is technical, there’s a lot more flexibility with (2) and (3). The UX lever becomes a lot more potent when you hit technical constraints you can’t overcome. That’s exactly what I did. Principle (3) doesn’t prescribe anything about existing Feature Flags. So, to overcome the technical constraint, we added a new UX constraint: People can’t reuse existing feature flags.
Note:
Next time I’m leading a project, I should make the principles explicit. They stay in my head most of the time, but it ought to be very helpful for the team to know them as well: it’s valuable context that helps everyone make decisions.
Build
We’ve now figured out the principles thanks to the usecase we’re solving for, and have a solution in mind. I want to move the quickest when building.
As the owner, my biggest responsibility here is setting priorities. Priorities help everyone move quickly and get shit done. I’ve been heavily influenced by Scott Berkun’s post on making things happen.
This means creating an ordered list of tasks that need to get done to achieve your goals. For huge projects, I might use a Kanban board, but for smaller ones, a single GitHub issue seems ideal. For example, here’s one I created for Experimentation.
In most cases, I get a MVP out first. Choosing what parts are important needs the right priorities set. Does it need proper UIs or not? Can it work with mock data? What’s the smallest working expression of our first principles?
The first project I led, I faced this whirlwind of tasks when building: there’s so many fucking things to do: a few people who need my help with stuff, figuring out designs, doing PR reviews etc. etc. A few days into the implementation had me juggling between all of these. I was moving around a lot, without getting much done. The core problem, I realised, was that I’d jump on whatever was dropped on my plate.
If I’m coding something up, and a PR request comes in: since no one else will be reviewing this, and I’m the owner - I’d want to unblock others quickly so they can keep moving fast - I’d drop what I was doing, do the review first, and then get back on whatever I dropped. Like a stack, last in first out.
This is terrible prioritisation. I had read Scott’s blogpost a while ago, but feeling it viscerally was what made it click for me: I need to get my priorities in order & follow through on them. This resolved things much better. I got rid of the thrashing problem by using a better scheduling algorithm. Whatever is the highest priority gets done first, no matter what comes in.
This ties back into how important the first two steps are. If you skipped them before building, your goal would simply be “build an A/B Test platform”. You’d have a much harder time prioritising because you lack context, and don’t know principles you can’t compromise on.
Being effective here also means keeping people on the same page, and ensuring that they can be productive. With more than a few people, I imagine this can get hard. I’ve only led very small teams (1-3 people), so things have been smooth so far.
I also appreciate my manager’s job a lot more now. I need to think about what every person does, and how they work. Given how the Big 5 Personality test accurately represents people in 5 dimensions, I’d hypothesize most people are categorizable. There’s only a few dimensions to them.1
Like a Fourier Transform, instead of working with those 5 dimensions, it’s more effective to work in dimensions that are easier to measure at work. I’m yet to figure these out completely (too few experiences dealing with people), but a few dimensions that stand out:
- Do they ask for help if they get stuck.
- To be productive, do they need me to (a) just set context; or (b) micromanage.
- What are their strengths?
-
Are they gear-driven or behaviour-driven?
I’m very gearsy - which means when I propose UX designs, I tend to go for “transparent internals” approach. As I’ve come to see, this is almost always the wrong thing to do. Most users don’t care about how their problems are solved, just that there’s a button which solves them.2
- ????
I think what makes management even easier at smaller companies is that most people are around the same on these dimensions, because the interview process selects for this. For example, at PostHog, once context is set, you can let people do what they feel is the most important.
I appreciate how I’m a complete n00b at management. But then again, I don’t think just adding years is going to make me better at it. Like I said in the introduction, if I don’t understand what I’m doing and why I’m doing it, I can’t improve quickly. Hence, my hypothesis on management.
Hopefully, you’re effective enough that you and your teammates get an MVP out. The next step is gathering feedback.
Gather Feedback
The best way I’ve found so far is doing user interviews. Nothing compares to the high fidelity one on one feedback, where you can go deep into whatever they say.
When gathering feedback, there’s two important things you’re testing:
-
Whether the principles you arrived at are indeed the first principles.
It’s easy to misunderstand what users really want. With a concrete MVP in place, you could ask hypotheticals like: “How would you do
<Important Thing>if this feature didn’t exist?”. You’re looking for confirmation that the information you gathered in the first step is still valid.For example, with experimentation, I would go deep into what users mean by the results being easy to understand. Is us telling them that A has a 85% chance to beat B good enough? Do they need more information? Why?
-
Whether your solution is a reasonable expression of those first principles.
Don’t just confirm you’re on the right track; ensure you actually solve the problems. Paolo, PostHog’s Product Manager, does this by giving users challenges. For example, “Say you want to create a new experiment. How will you do it?”. I often follow up with questions, like ‘What do you think this graph means?’ or ‘Why are you getting that warning?’
After these challenges, it’s a good idea to ask for general feedback: What’s missing? What do you love? Did this solve your problem?
At the end, you want to come out with two things: (1) Do users love this? and (2) If not, what’s missing? What do you need?
Align metrics with feedback
Just having happy users in feedback calls isn’t enough. I always need to ensure that metrics line up with what users are saying.
I like to go through two cycles of Gather context -> Figure out solution -> build -> gather feedback. At this point, things are usually good to go. If I’m doing things right, the second cycle is much faster: it’s adding on functionality that we skipped in the MVP, so the gathering context & figuring out solutions steps can mostly be skipped.
At this stage I’ll add analytics support (i.e. start sending in events about how users are using the product), start releasing to a % of the world, and see how things go. You ought to be able to answer questions like: “How many people are using it?”, “Of the people using it, how many find it valuable?”, and any other relevant product questions.
I build a dashboard of metrics for every product I’ve worked on, and check it every Friday. This is important in the early weeks right after you launch, since it shows you if there are bugs with event capture, and if you can answer all questions you have about the product. If I can’t tell which part of this product is most popular, I’m probably lacking event instrumentation: I should add those missing events as soon as possible. Otherwise, I’m flying blind.
Usually, it takes longer for patterns to show up in metrics. At this point, I’ll put the project in background mode, wait for user patterns to show up, and then decide what I want to do about it.
For example, with my first ever project, correlation analysis, our usage funnel today looks something like this:
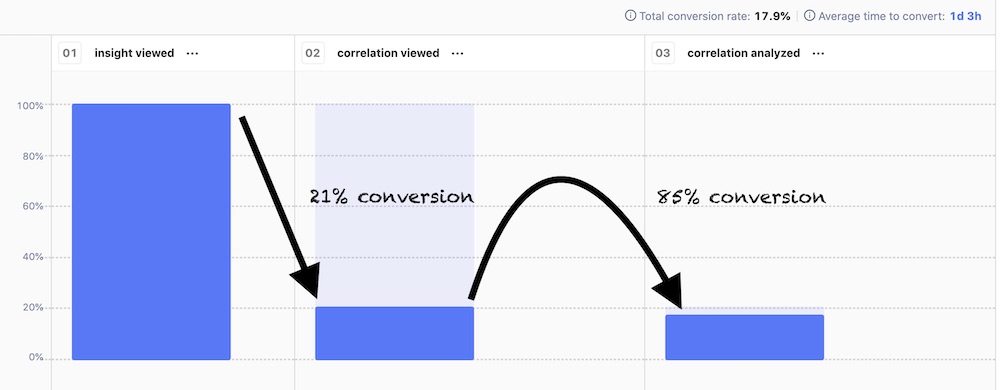
People love correlation analysis a lot, as evident by the 85% conversion rate for the second step. The problem is discovery: most people don’t know it exists. So, whenever I come back to it next, the problem I’d want to solve is making it more discoverable.
Meta: Create feedback loops
A common theme across all the steps I want to highlight is feedback loops. To work quickly & to make sure you’re doing the right things, you need several feedback loops. Both, long term and short term.
Each step above has its own quick feedback loops, where you get feedback within hours.
For example, when gathering context, don’t do it in a silo. Do it with your teammates (specially product owners). Explore competitor products together. Make the thread open, so everyone in the company can see and contribute to it. It’s valuable to hear from colleagues who might have more context because they were an insider.
In the building phase, fast feedback loops mean small pull requests and quick reviews! Imagine how much faster you get things done and how much better your code looks when you have small PRs that get reviewed quickly, vs. a 500 line change that takes ages to get reviewed.
Apart from these quick feedback loops, there are slower but still important feedback loops between consecutive steps. The stage outputs aren’t set in stone. There’s going to be times when things come up that you didn’t think about earlier.
New technical constraints might show up while implementing the solution, that forces you to go back to the “figuring out the solution” stage. Don’t get married to the initial idea you came up with. Divorces are hard.
While working on experimentation, we decided to allow reusing an existing Feature flag to do experiments. This made sense because people would create the feature flag, test the A & B versions look alright, and then use that same feature flag in an experiment, without having to do any code changes.
However, during implementation I realised this clashed with one of the principles. Making things work like this meant the results would not be 100% accurate.3 So, as I mentioned above, we came up with the extra constraint of not re-using feature flags, and generating code snippets to explain how to test with this new feature flag.
Finally, the longest feedback loops come with usage over time. This means tracking your metrics properly. The final step, “aligning metrics with feedback” is precisely this: a long feedback loop that gets rid of the noise and shows you exactly how users are using this product.
The meta is to always create feedback loops.
Meta: Manage your Emotions
When I led my first project, something switched. For the first time, I felt this responsibility of getting shit done myself - there’s no one else I can fall back on. This led to me being a lot more “switched on”. I found it hard to switch off after work. I worried about whether I’ll hit my self-imposed deadlines, about technical challenges we haven’t yet solved, and whether I’ll succeed or not.
I love switching off after work. This is wonderful for my mental health, and allows me to freely enjoy my other hobbies outside of work. So, I knew that owning projects where I’m always switched on like this wasn’t feasible.
This was all on me: I wasn’t used to leading projects, and that took a toll on me.
The next time around, things were a lot more stable. I don’t know what changed, but I felt a lot more in control. I think familiarity with the process helped me face this anxiety better. Not surprisingly, I’ve faced something like this every time I’m trying something new. It’s a feeling I’ve come to accept.
Another thing I noticed was that anxiety towards the end of a project shot up. The MVP felt easy: there’s no polishing required, it’s just the concept, get it out and you’re good. The project isn’t done with the MVP though. To finish, you actually need to tie up all the loose ends and polish the UI. The closer I got to finishing, the more I worried. I think a big part of this was that I had never built a pretty frontend before (every frontend I built before looked like shit). It was an unknown that I didn’t care about earlier, because I knew there’s atleast a few people at PostHog who are very experienced at building pretty things. Working through this unknown myself was very useful: it helped me face my “fear” and gain confidence in an area I was unfamiliar.
Since I was the project owner, it would’ve been just as easy to pass this work onto someone else. But noticing what I was doing and why I was doing it helped me make better decisions.
I don’t have much to offer in terms of what to do about emotions. They come, change your direction, and flitter away. What I’ve found helpful is noticing these emotions. Notice how you’re feeling and why you’re feeling that way. It gives me clarity, and just doing this is enough to make better decisions.
Conclusion
Each of the 5 steps above are crucial. They bring something important to the table, and I suspect are necessary for every successful product.
I figured the hard part of software engineering was building things. But now, maybe it’s figuring out what to build. Knowing what to build seems rarer. That’s surprising to me, since you don’t need to know how to code to figure out what to build.
There are probably more subtle things I’m doing wrong (and right), which I haven’t been noticing yet. But this post is my playbook: new things I notice get inserted into one of these steps, warnings get added, and I keep getting better and better.
Wrapped in here is the third meta: To improve quickly, you need to know what you’re doing and why you’re doing it.

-
It’s hard for me to believe that everyone is unique, etc. etc. Most people seem to have similar lives and the same problems. ↩
-
A bit of an overgeneralisation, depends a lot on the context/industry/solution. But since I’m too gearsy, phrasing it this way ensures I take it seriously. ↩
-
Not because the feature flag is already in use, but because of the type of feature flag. Real details here ↩
You might also like
- AI Made Me Braver
- How I'm Productive with Claude Code
- Agentic Debt
- What I learned about burnout and anxiety at 30